
LangWatchاستوديو تحسين نماذج اللغات الكبيرة (LLMs) لمراقبة وتقييم وتحسين تطبيقات الذكاء الاصطناعي المدارة في الإنتاج.

نظرة عامة
الميزات الرئيسية
- رقابة النموذج اللغوي والتعقب
- أنابيب التقييم الآلي
- إدارة الاستدعاءات والبيانات
- تحليلات الجودة والتكلفة
- أدوات تحسين لسلاسل والوكلاء
- SDKs لأطر العمل الشائعة للنموذج اللغوي
التسعير
- النموذج
- Freemium
- الفئة
- Research Assistants
- التقييم
- 4.6 / 5 (5)
حالات الاستخدام
مراقبة تطبيقات النموذج اللغوي في الإنتاج
تتبع حركة النموذج اللغوي الحية، تتبع معايير الجودة والتكلفة، واكتشاف الانحدارات قبل التأثير على المستخدمين عبر تطبيقات الذكاء الاصطناعي الموزعة.
تقييم الاستدعاءات الآلي
chạy أنابيب التقييم الآلي ضد مجموعات البيانات المحددة لتقديم نموذج الاستدعاءات والتغييرات بالنتائج القابلة للقياس والمتكررة.
تصحيح واختبار الوكلاء
فحص سلاسل وأثر الوكلاء لتحديد نقاط الفشل، وتكرار الاستدعاءات، وتحسين الموثوقية باستخدام ملاحظات الأداء.
تتبع الاتجاهات التكاليفية والجودة
تحليل تحليلات التكلفة والجودة عبر إصدارات النموذج للتوازن بين الإنفاق مقابل جودة الإخراج وتوجيه القرارات التشغيلية.
المزايا والعيوب
المزايا
- منصة متكاملة لمعالجة المشاكل الرئيسية في تطوير الذكاء الاصطناعي
- عمليات التقييم المتكررة والأدوات المتعددة للمساعدة في اتخاذ القرارات الأمثل
- تحليلات استخدام LLM والتكلفة عبر الإصدارات
- التكامل مع أدوات الذكاء الاصطناعي واللغات الشائعة لدعم سير عمل التقييم الآلي لنماذجك
- تعزيز معالجة اللغة الطبيعية وحلول ذكاء الأعمال ببيانات عالية الجودة وتحسين نماذج AI through automation
العيوب
- يركز بشكل أساسي على فرق الذكاء الاصطناعي الفنية
- يتطلب أداة تحليل للاستفادة الكاملة
- منحنى التعلم لإعداد التقييم
المراجعات
المتوسط من 5 تقييم.
سجّل الدخول لكتابة مراجعة.
Does the job
Pretty happy overall. Automated evaluation pipelines just works and integrates with common LLM frameworks and providers. but no dealbreakers — I'd recommend it to a friend without hesitating.
Does the job
Pretty happy overall. Automated evaluation pipelines just works and supports prompt and pipeline iteration with metrics. Requires instrumentation to get full value can be annoying, but no dealbreakers — I'd recommend it to a friend without hesitating.
Skeptical, then convinced
I went in skeptical — most tools in this space overpromise. It actually delivers on automated evaluation pipelines, and helps catch quality regressions before deployment caught me off guard. Requires instrumentation to get full value is why this isn't a perfect score, still, I'd recommend giving it a real trial.
Skeptical, then convinced
I went in skeptical — most tools in this space overpromise. It actually delivers on prompt and dataset management, and unified monitoring and evaluation in one workspace caught me off guard. still, I'd recommend giving it a real trial.
Compared a few options
Evaluated this against two competitors. Where it wins: lLM observability and tracing and helps catch quality regressions before deployment. Where it lags: requires instrumentation to get full value. On balance the feature set — especially optimization tooling for chains and agents — justifies the 4 stars for our use case.
أسئلة وأجوبة
لا توجد أسئلة بعد — كن أول من يسأل.
اطرح سؤالاً
بدائل لـ Research Assistants
LevelFields AI
Research Assistants
منصة مدفوعة بالذكاء الاصطناعي تجمع أفكار صفقات تداول الأسهم المرتبطة بالفعاليات التاريخية وتسرع البحث الاستثماري.
Foundry.ai
Research Assistants
Foundry.ai: استوديو تكنولوجيا يعزز الابتكار الذكاء الاصطناعي بالتعاون مع شركات Global 2000.
Chemcrow
Research Assistants
الكذب الافتراضي المدعوم بنموذج اللغة الكبير الكيميائي
Atria by Senso Labs
Research Assistants
مساعد الذكاء الاصطناعي للمحترفين المعماريين يسهل الالتزام بالبناء وتحليل الاستدامة واسترجاع البيانات المتعلقة بالمشروع.
WhispriNote
Research Assistants
حوّل المحاضرات المسجلة إلى ملاحظات دراسية
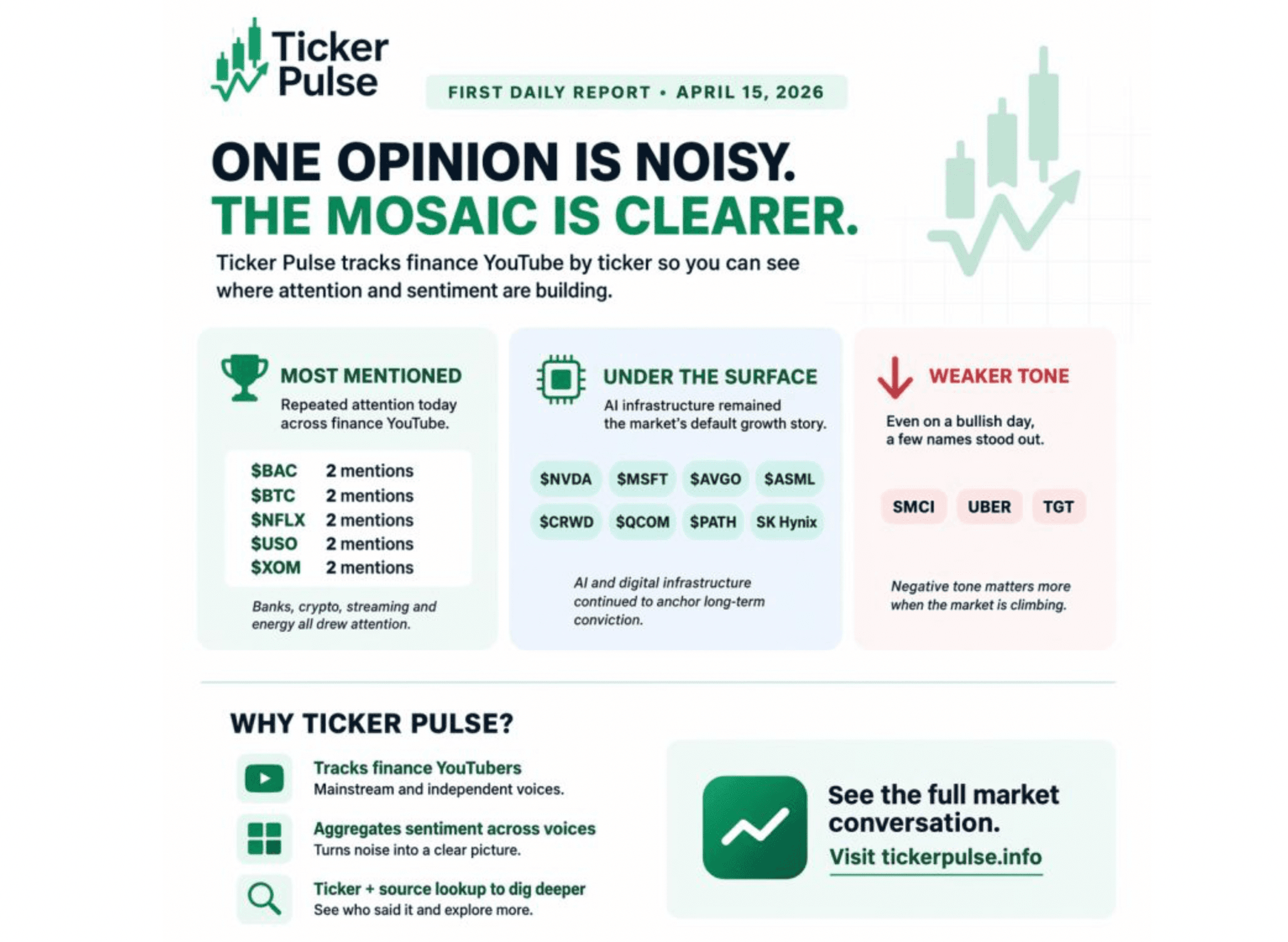
Ticker Pulse
Research Assistants
اكتشف اتجاهات السوق قبل أن تصبح أخباراً رئيسية
Unhosted AI
Research Assistants
مساعد تحليلات العملات الرقمية المدعوم بالذكاء الاصطناعي لاتخاذ قرارات تداول أكثر ذكاءً وقائمة على البيانات.
Legora
Research Assistants
منصة ذكية تعاونية للذكاء الاصطناعي تساعد الفرق القانونية على المراجعة والمسودة والبحث بشكل أسرع بدقة وقابلية للتوسيع.
Trending now
Reducto AI
AI Agent Development Platforms
فتح البيانات المقفلة من المستندات المعقدة
AdCrier
Marketing & Advertising
مشاركات ممولة بناءً على السياق، لا تتبع المستخدم أو بيانات
Pin AI
Workflow automation
مساعد الذكاء الاصطناعي للبحث عن المواهب بشكل فعّال: يسرع Pin AI عملية التوظيف مع الحفاظ على جودة الاختيار.
Midjourney
Image Generation
إنشاء صور مذهلة من النصوص