
ProlificПлатформа з людськими даними для тренування AI, з 200 000+ перевірених учасників за потребою

Огляд
Ключові функції
- Доступ до понад 200 000 активних людей‑виконавців
- Перефільтри демографічного та поведінкового попереднього відбору
- Підтримка опитувань, маркування та завдань RLHF
- Перевірка ідентифікатора учасника та контроль якості
- Керовані послуги для масштабних проектів з даними
- API та інтеграції для дослідницьких робочих процесів
Ціни
- Модель
- Freemium
- Категорія
- AI-агенти
- Рейтинг
- 4.6 / 5 (5)
Кейси використання
Збір відгуків RLHF для налаштування LLM
Наймайте перевірених людських оцінювачів, щоб порівнювати результати моделей і надавати дані переваг, що підтримують процес підкріплювального навчання з людського відгуку.
Проведення демографічно орієнтованих дослідницьких опитувань
Запускайте опитування з деталізованими фільтрами попереднього відбору, щоб збирати репрезентативні відповіді по конкретним віковим, географічним або поведінковим сегментам для досліджень AI.
Порівняння результатів моделей із людьми
Порівнюйте відповіді, створені AI, з відповідями реальних учасників, щоб оцінити точність, узгодженість та якість моделей у відкритих завданнях.
Масштабування аннотацій за допомогою керованих послуг
Використовуйте керовані послуги для координації великих або складних проектів позначення, використовуючи учасників з перевіреним ID та інтегровані робочі процеси API.
Плюси і мінуси
Плюси
- Великий, різноманітний пул попередньо перевірених учасників
- Швидкий набір з детальними демографічними фільтрами
- Сильна репутація у академічних та AI дослідницьких спільнотах
- Вбудовані справедливі умови оплати та етичні стандарти участі
Мінуси
- Вартість швидко зростає з розміром вибірки та фільтрацією
- Менш підходить для високо спеціалізованих експертних позначок
- Пул схиляється до західних, англомовних регіонів
- Самостійні інструменти для складних завдань можуть бути обмеженими
Відгуки
Середнє з 5 оцінок.
Увійди, щоб залишити відгук.
Solid for our team
We rolled this out across the team last quarter and fast recruitment with detailed demographic filters. Participant ID verification and quality controls fits neatly into how we already work, and demographic and behavioral prescreening filters removed a step we used to do by hand. Less suited for highly specialized expert annotation, which is the main caveat, but it has held up under daily use.
Skeptical, then convinced
I went in skeptical — most tools in this space overpromise. It actually delivers on access to 200k+ active human taskers, and large, diverse pool of pre-vetted participants caught me off guard. still, I'd recommend giving it a real trial.
Compared a few options
Evaluated this against two competitors. Where it wins: aPI and integrations for research workflows and large, diverse pool of pre-vetted participants. Where it lags: less suited for highly specialized expert annotation. On balance the feature set — especially managed services for large-scale data projects — justifies the 4 stars for our use case.
Skeptical, then convinced
I went in skeptical — most tools in this space overpromise. It actually delivers on aPI and integrations for research workflows, and strong reputation in academic and AI research communities caught me off guard. Pool skews toward Western, English-speaking regions is why this isn't a perfect score, still, I'd recommend giving it a real trial.
Compared a few options
Evaluated this against two competitors. Where it wins: managed services for large-scale data projects and built-in fair pay and ethical participation standards. On balance the feature set — especially participant ID verification and quality controls — justifies the 5 stars for our use case.
Питання
What types of AI data tasks can I run on Prolific?
You can run surveys, data labeling, RLHF feedback collection, and model output benchmarking against human responses. It supports both data generation and evaluation workflows for AI training and research.
What are Prolific's main limitations for specialized or large-scale projects?
Costs scale quickly with sample size and screening, and the pool skews toward Western, English-speaking regions, making it less suited for highly specialized expert annotation. Self-serve tooling can feel limited for complex tasks, though managed services are available.
How does Prolific ensure participant quality?
Prolific uses ID verification, fair pay standards, and granular demographic and behavioral prescreening filters to vet its 200k+ active taskers. These quality controls have made it popular with academic researchers and commercial AI labs.
Постав питання
Альтернативи AI-агенти
Zapier's Agents
AI-агенти
AI-агенти, що автоматизують робочі процеси в більш ніж 7 000 підключених додатків
NexusGPT
AI-агенти
Платформа без коду для створення та розгортання користувацьких агентів штучного інтелекту для автоматизації бізнес-робочих процесів.

AgentForge
AI-агенти
Потужний низько-кодовий фреймворк для створення незалежних агентів AI та когнітивних архітектур
Maps Scraper AI
AI-агенти
Інструмент, що керується AI, який автоматизує видобування інформації про бізнес із Google Maps, підвищуючи покоління лідерів та дослідження ринку.

Momentic AI
AI-агенти
Пишіть, виправляйте та запускайте програмні тести за допомогою простих англійських підказок.
Micro Agent
AI-агенти
ШІ-кодовий агент, який ітерує код до тих пір, поки ваші тести не пройдуть
Mogoj AI
AI-агенти
Оптимізація робочого процесу на основі ШІ та автоматизація бізнес-процесів
Charisma.ai
AI-агенти
Іммерсивна мовна AI для інтерактивної розповіді, навчання й маркетингових кампаній.
Trending now
Midjourney
Генерація зображень
Генеруйте приголомшливі зображення зі тексту
Doozer Ai
Sales Agent
Цифрові колеги, які автоматизують операційні процеси для підвищення ефективності команди.
EmblemAI
DeFi-агенти
Повноцільний криптовалютний асистент з AI для управління активами на різних блокчейнів.
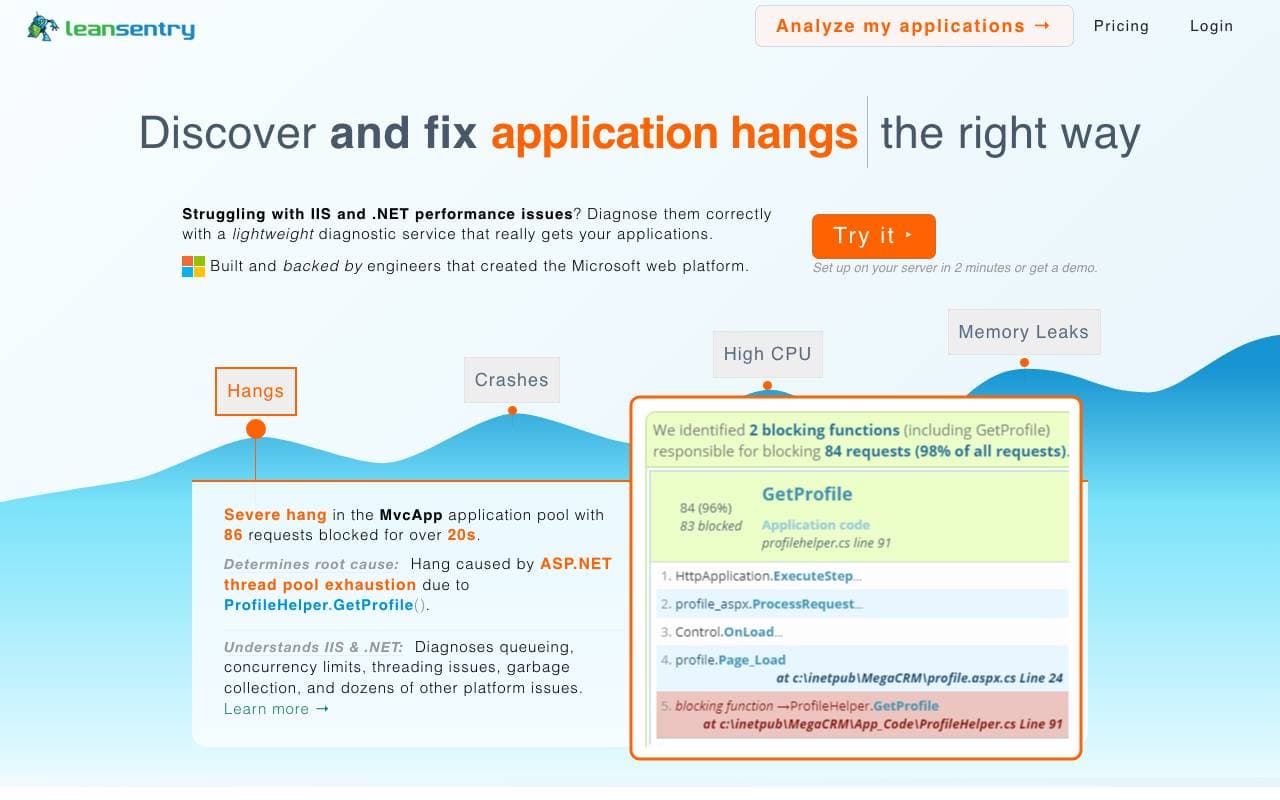
LeanSentry
Розробка програмного забезпечення
Надаємо інтелектуальну допомогу з діагностикою та мониторингом для вирішення проблем з ІІС та ASP.NET виконавчої продуктивності.