
Chroma AIBase de données d'applications d'IA ouverte source avec outils inclus pour la gestion de la chargement et de l'indexation des embeds et des données de métadonnées

Aperçu
Fonctionnalités clés
- Stockage de vecteurs avec filtrage de métadonnées
- SDK Python et JavaScript
- Modes embarqué ou client-serveur
- Prise en charge intégrée de la fonction d'embedding
- Intégrations LangChain et LlamaIndex
- Hébergement cloud géré en option
Tarifs
- Modèle
- Freemium
- Catégorie
- Software Development
- Note
- 4.5 / 5 (4)
Cas d’usage
Modèles de langage large (LLM) et analyse de documents à des butins
Stockez les documents et les informations sur vos modèles de langage large (LLM) et approvisionnez votre application grâce à une API simple pour les applications IA.
“De plus grandes applications de Recherche et de Génération (RAW) nécessitent des bases de données évoluées, mais les modèles de langage large (LLM) et des bases de données s'appuyent sur Chroma, avec une API simple pour les applications IA.”
Invalidation de triage de documents pour des applications linguistiques.
Stockez tous vos documents et des informations sur vos modèles de langage large (LLM) et obtenez la mise en pièce pour votre application grâce à une API simple pour les applications IA.
“Les applications linguistiques elles appelles des bases de données évoluées, mais les modèles de langage large (LLM) et la base de données reposent sur Chroma, avec une API simple pour les applications IA.”
Remplissage de pièces d'application de base pour des applications linguistiques.
Rapportez vos documents et des informations sur vos modèles de langage large (LLM) et des bases de données de façon simple pour les applications IA.
“Les applications linguistiques sont basées sur des bases de données évoluées, mais Chroma fournit des modèles de langage large (LLM) et des bases de données qui se base sur des API simple pour les applications d'IA.”
Modèles de langage large (LLM) de base pour des applications linguistiques.
Indexez vos documents et informations sur vos modèles de langage larges (LLM) et des bases de données de façon simple pour les applications d'IA.
“Les applications linguistiques sont constituées d'une base de données évoluée, mais Chroma fournit des modèles de langage larges (LLM) et des bases de données qui se base sur des API simple pour les applications d'IA.”
Rapportez-vous réflexions de base pour des applications linguistiques.
Intégrez vos documents et des informations sur vos modèles de langage large (LLM) et des bases de données de façon simple pour les applications d'IA.
“Les applications linguistiques sont constituées d'une base de données évoluée, mais Chroma fournit des modèles de langage larges (LLM) et des bases de données qui se base sur des API simple pour les applications d'IA.”
Modèles de langage large (LLM) de base pour des applications linguistiques.
Intégrez vos documents et des informations sur vos modèles de langage larges (LLM) et des bases de données de façon simple pour les applications d'IA.
“Les applications linguistiques sont constituées d'une base de données évoluée, mais Chroma fournit des modèles de langage larges (LLM) et des bases de données qui se base sur des API simple pour les applications d'IA.”
Pour & contre
Pour
- Gratuit et ouvert
- API simple pour des applications AI
- Base de données simple pour les applications de modèles de langage large (LLM)
- Application rapide de pipelines RAG
- Prestations d'un API simple pour les applications AI
Contre
- Nouveau opérateur
- Utilisation interne de Python ou d'JavaScript pour la rapidité
- Hebergement pour des applications LangModèle de langage large (LLM)
- Accès rapide à des pipelines RAG
- Fourniture d'un API simple pour les applications AI
Avis
Moyenne sur 4 avis.
Connecte-toi pour laisser un avis.
Years in this space
I've evaluated a lot of these over the years. What stands out here is embedded or client-server modes — handled better than most — and free and open source. Worth the time if this is your use case.
Skeptical, then convinced
I went in skeptical — most tools in this space overpromise. It actually delivers on embedded or client-server modes, and simple, developer-friendly API caught me off guard. still, I'd recommend giving it a real trial.
Solid for our team
We rolled this out across the team last quarter and simple, developer-friendly API. Built-in embedding function support fits neatly into how we already work, and langChain and LlamaIndex integrations removed a step we used to do by hand. Newer project, still maturing, which is the main caveat, but it has held up under daily use.
Years in this space
I've evaluated a lot of these over the years. What stands out here is built-in embedding function support — handled better than most — and works locally or as a server. Newer project, still maturing is my one real gripe. Worth the time if this is your use case.
Questions & réponses
Pas encore de question — sois le premier à demander.
Poser une question
Alternatives à Software Development
Rectify
Software Development
Assistant de débogage intelligent qui aide les développeurs à trouver et à corriger rapidement les bogues dans le code généré par IA.
SwarmStack
Software Development
Agent de l'intelligence artificielle pour la planification, la délimitation et les recommandations de construction de produits
Warp AI
Software Development
Terminal alimenté par IA qui transforme le langage naturel en commandes shell et en flux de travail.
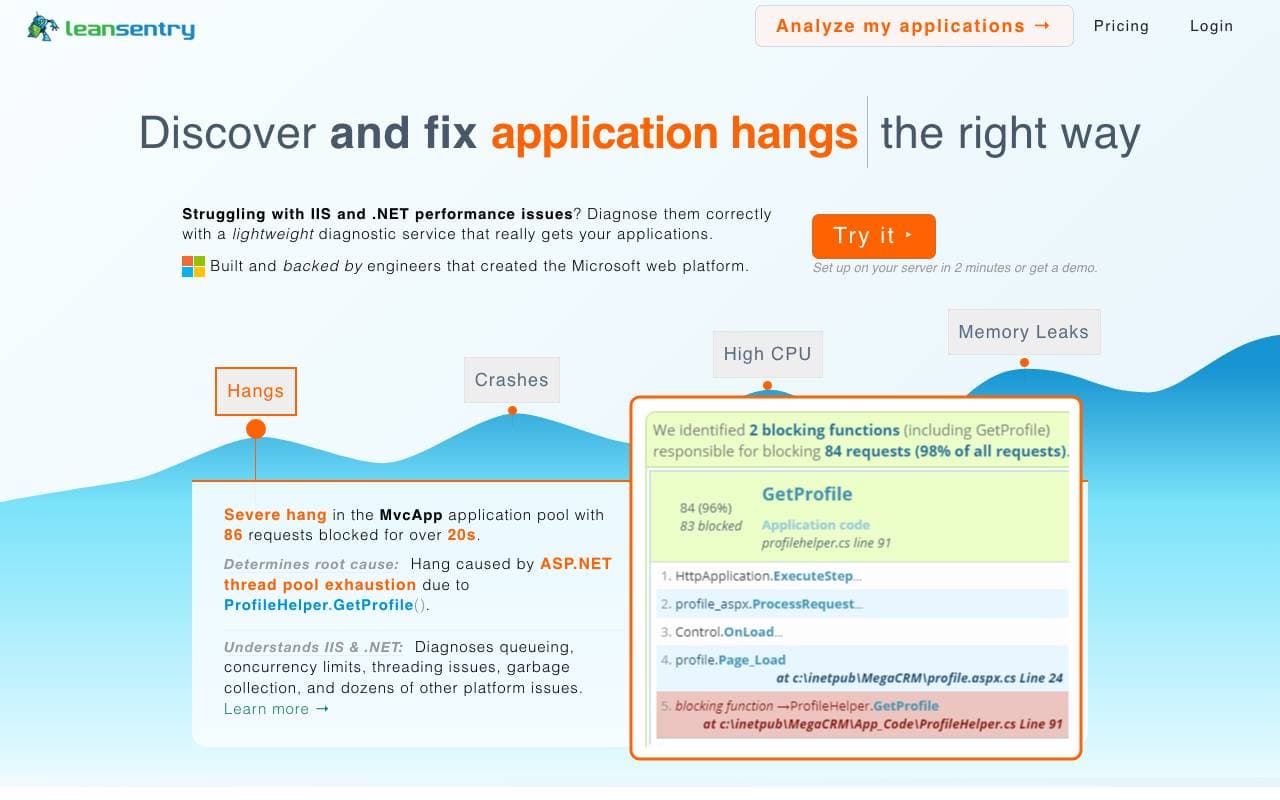
LeanSentry
Software Development
Diagnostics et surveillance pilotées par l'IA pour les problèmes de performances d'IIS et ASP.NET
CopyChecker AI Reverse Image Search
Software Development
Recherche d'images inversée pour retrouver les sources originales et détecter les doublons ou les images similaires
OG Pilot
Software Development
Générateur d'images Open Graph à un clic pour des aperçus de lien plus rapides et plus attrayants.

Plexe
Software Development
Construire des modèles de machine learning personnalisés à partir de prompts de langue naturelle

Wrapifai
Software Development
Construire des outils mini-IA sans code pour attirer le trafic naturel et générer des leads
Trending now
Claude
AI Agents & Chatbots
Assistant IA conversationnel d'Anthropic pour la rédaction, l'analyse, la programmation et les tâches documentaires
LeanSentry
Software Development
Diagnostics et surveillance pilotées par l'IA pour les problèmes de performances d'IIS et ASP.NET
Doozer Ai
Sales Agent
Les co-travailleurs numériques qui automatisent les workflows opérationnels pour augmenter l'efficacité de l'équipe.
Consistent Character AI
Images
Générez des personnages IA cohérents à travers des scènes à partir d'une seule photo de référence.